现如今信息茧房的概念,大家已经非常熟悉了,但我也想再啰嗦一遍。
信息茧房是指个体由于个人偏好,仅接触到限定范围内的信息,这种现象会导致个体的视野逐渐缩窄。这个概念由凯斯·桑斯坦提出,与回声室效应和过滤泡泡有相似之处,主要关注信息多样性的缺失问题。信息茧房的形成受到大数据、用户行为及推荐算法的共同影响,虽然这增加了用户粘性,却同时限制了信息的多样性,进而可能催生群体之间的极化现象。 —— 信息茧房
在此,我想先重申一下「互联网精神」即:开放、平等、协作、快速、分享。虽然互联网的快速发展似乎逐渐偏离了这一初衷,我们也不能否认商业化为其发展所做出的贡献。
关于信息茧房,我们同样应持辩证的观点来看待。一方面,算法定制化提供的高密度信息源,让我们能够足不出户就了解世界各地的新闻,例如对骑行有浓厚兴趣的人可以通过抖音迅速找到志同道合的圈子,何乐而不为呢?然而,另一方面,长时间接受这种定制化和高密度的信息推送,不仅剥夺了我们独立思考的能力,还可能导致思想的极端化。
我们长期只接触有限的信息源,最终就可能导致思维的僵化。虽然个人思维的固化并非不可逆转,但若是群体性地出现这种现象,则其后果无疑是非常可怕的。
因此,打破信息茧房的关键在于我们是否愿意主动寻求和接触多样化的信息源。
碎片信息源
我的碎片信息源,主要由 RSS 订阅提供。首先 RSS 是一种公开,异步,需要手动维护的信息源,它不仅可以用来订阅独立博客,还包括论坛帖子,时政新闻,财政报道,官方通知等多种内容。
基于我个人的实践经验,下面我将分享:如何利用 RSS 作为载体,高效打破信息茧房。
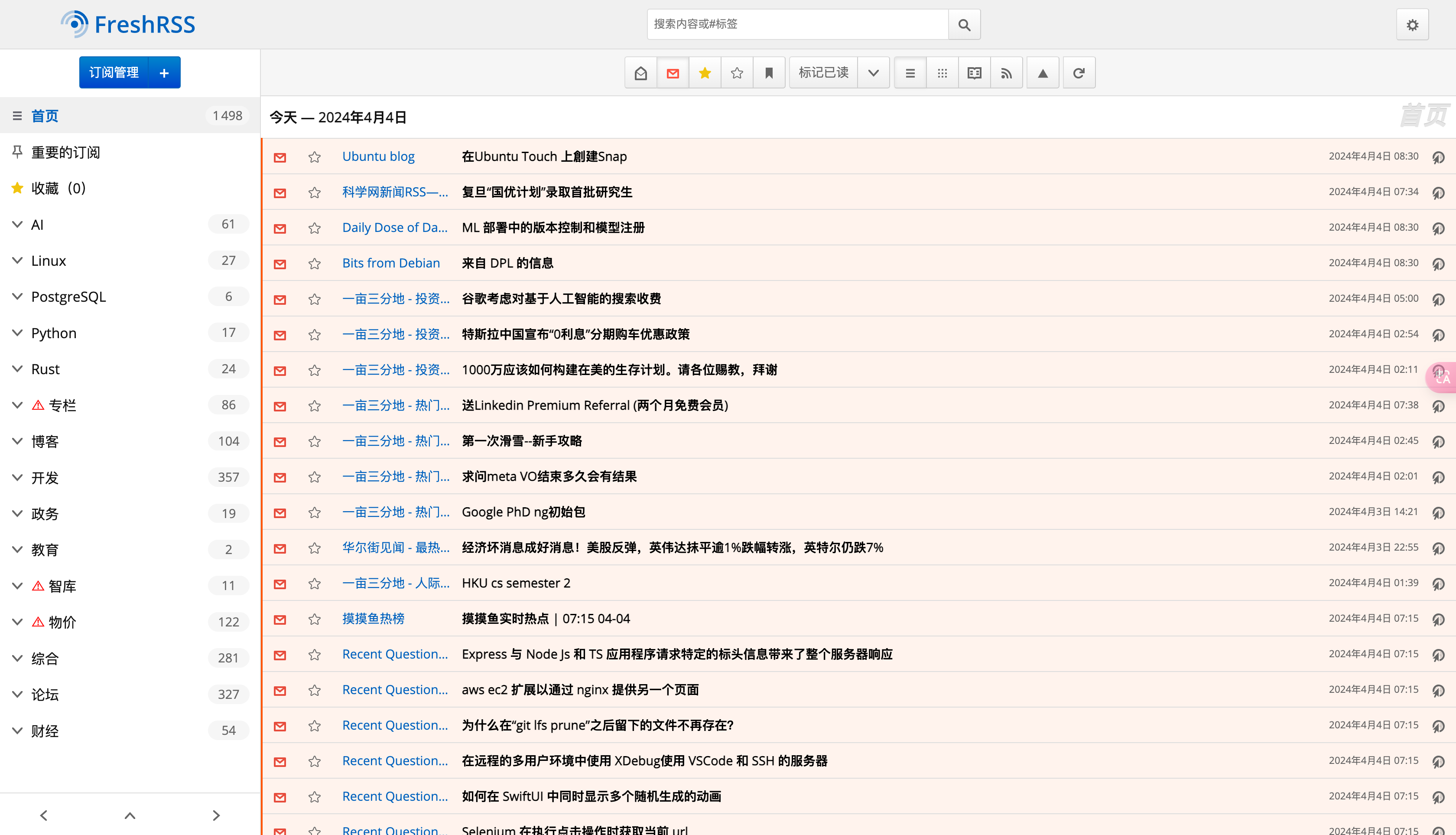
如图,我基于 FreshRSS 阅读器打造的 V2 版本 RSS 阅读器,关于 V1 版本在之前博文专题《数字文具盒》中有详细讲到。V2 版本主要针对使用流程和管理方法做了进一步优化。
关于 FreshRSS 阅读器搭建,互联网许多相关教程,这里我就不再叙述了。但我特别推荐兼容 FreshRSS 的移动客户端——FocusReader,无论是颜值还是实用性都是非常 ok 的。
前面我有说到 RSS 源是需要手动维护的,可千万别低估这一过程的复杂性,我相信很多人一定曾被折腾的,头一个比两个大。例如有些独立博客三天两头换域名、RSSHub 路由三天两头不能用、公开分享的 RSS 源乱七八糟、新的 RSS 源又不知道去哪里找。
RSS 信息源去哪里寻找?
我的 RSS 信息源主要来自三个渠道:互联网搜索,RSSHub 以及个人爬虫。这里我需要强调一点,务必要学会尝试不同语种的 RSS 信息源,融入全球互联网是非常有必要的。
通过谷歌使用主题 + 关键字,可以简单、高效找到所需信息源,并且通常是稳定的官方信息源。

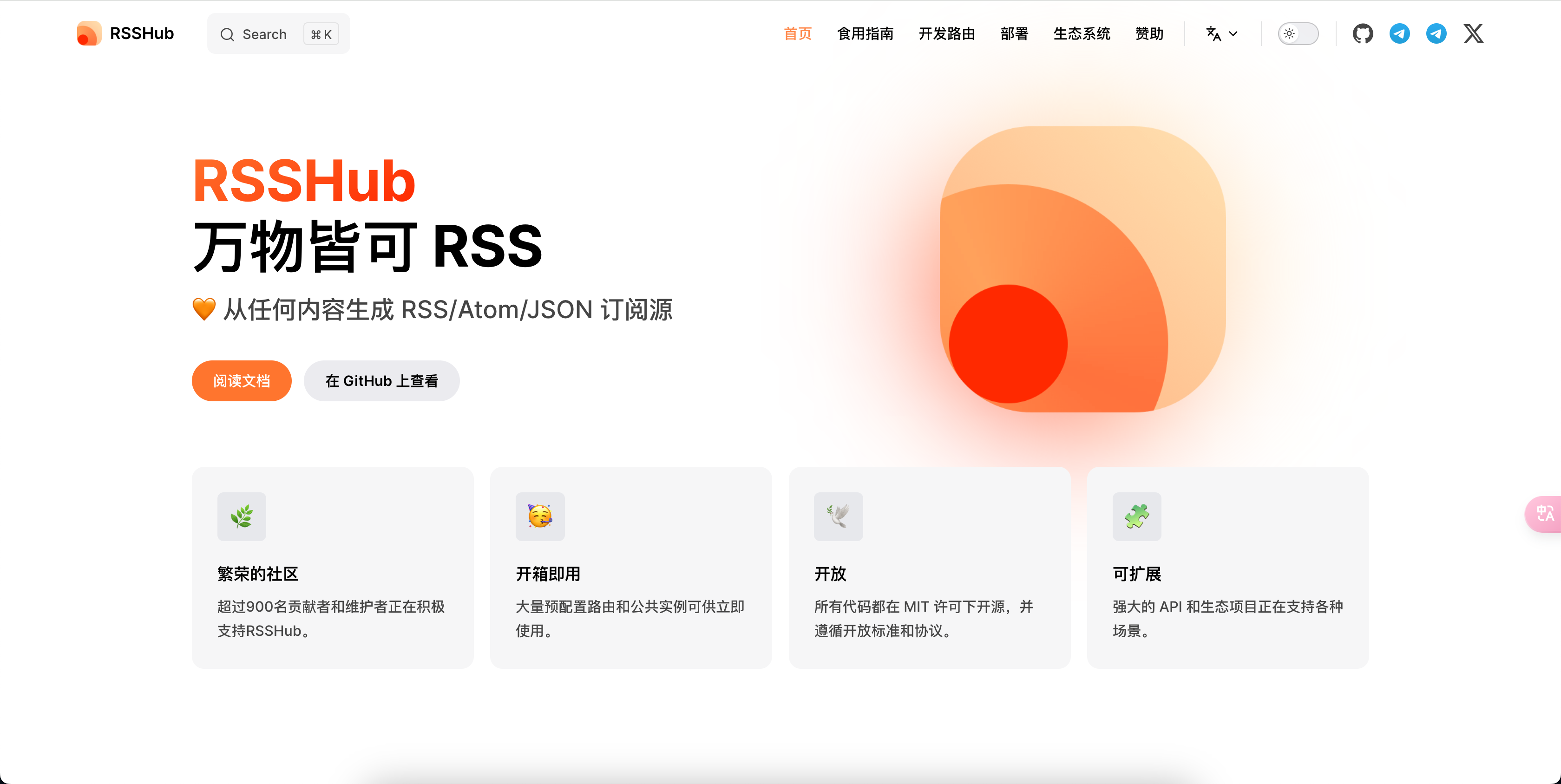
RSSHub 是专门为那些本身不提供 RSS 的网站提供订阅功能。我还开发了一个基于 Python 的 RSSHub 青春版,解决了 RSSHub 的一些不足,还可以满足一些特殊订阅需求。
RSS 信息源如何管理维护?
熵增定律,如果没有外力作用,系统内部会逐渐趋于混乱。
如果想要形成可靠,优质的 RSS 信息源,学会管理维护是至关重要的。主要包括如下步骤:
-
根据需求划分信息源主题。
-
分类整理 RSS 信息源。
-
定期更新维护无效信息源。
-
定期不断探索新的信息源。
如果是刚开始使用 RSS 的朋友,我建议维护一个每日能提供大约 3000 条信息更新的 RSS 源集合。注意,这并不是说 3000 个不同的信息源。因为有些 RSS 源一天能更新很多条内容,而有些一周可能只更新一次。然后随着慢慢深入使用可以自行调整删减。
目前我的 RSS 信息数量维持在 1000 ± 500 条左右,日常阅读大概需要花费我 45 ± 15 分钟左右。不过这个信息量具体取决于个人时间,可以自行调整。
对于随机尝试了解新的信息源,我是不喜欢漫无目的地阅读,容易左耳进,右耳出。只有我了解到新主题后,就会开始尝试搭建对应的 RSS 信息源体系。
RSS 信息源如何高效阅读?
首先如果 1000 条信息源,一条一条划着看,同时遇见优质信息再深入阅读,两个小时都不一定够。
下面分享三个,我用来提高阅读效率的 Chrome 插件:
读点东西 一个开源的 Chrome 插件,可以将网页转成阅读模式,并且内置了 AI 总结、翻译、Markdown 转换等功能。
这个插件目前不支持自定义 OpenAI 接口,作者似乎放弃了项目。其实也可以去 Github 替换一下接口地址, 然后 Chrome 安装自定义插件就行哈哈哈。如果有熟悉 TypeScript + Chrome 插件开发的,可以 Fork 一下造福全人类。
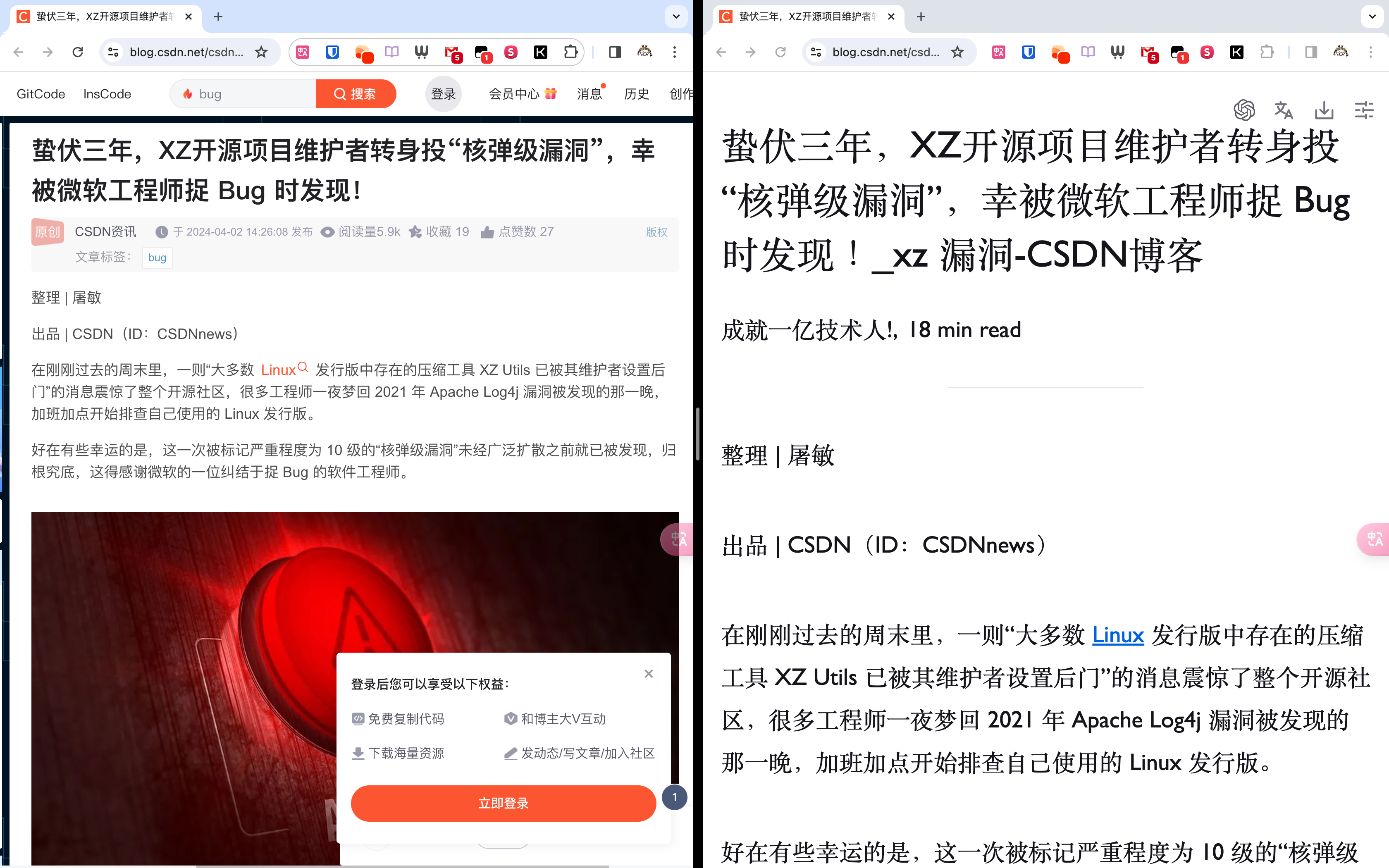
ChatGPT 总结助手 可以对任何网页进行总结,支持 GPT 3.5、GPT-4 等模型。如果你没有 ChatGPT 的 API,可以使用 one-api 反向代理使用国产大模型替代 OpenAI。
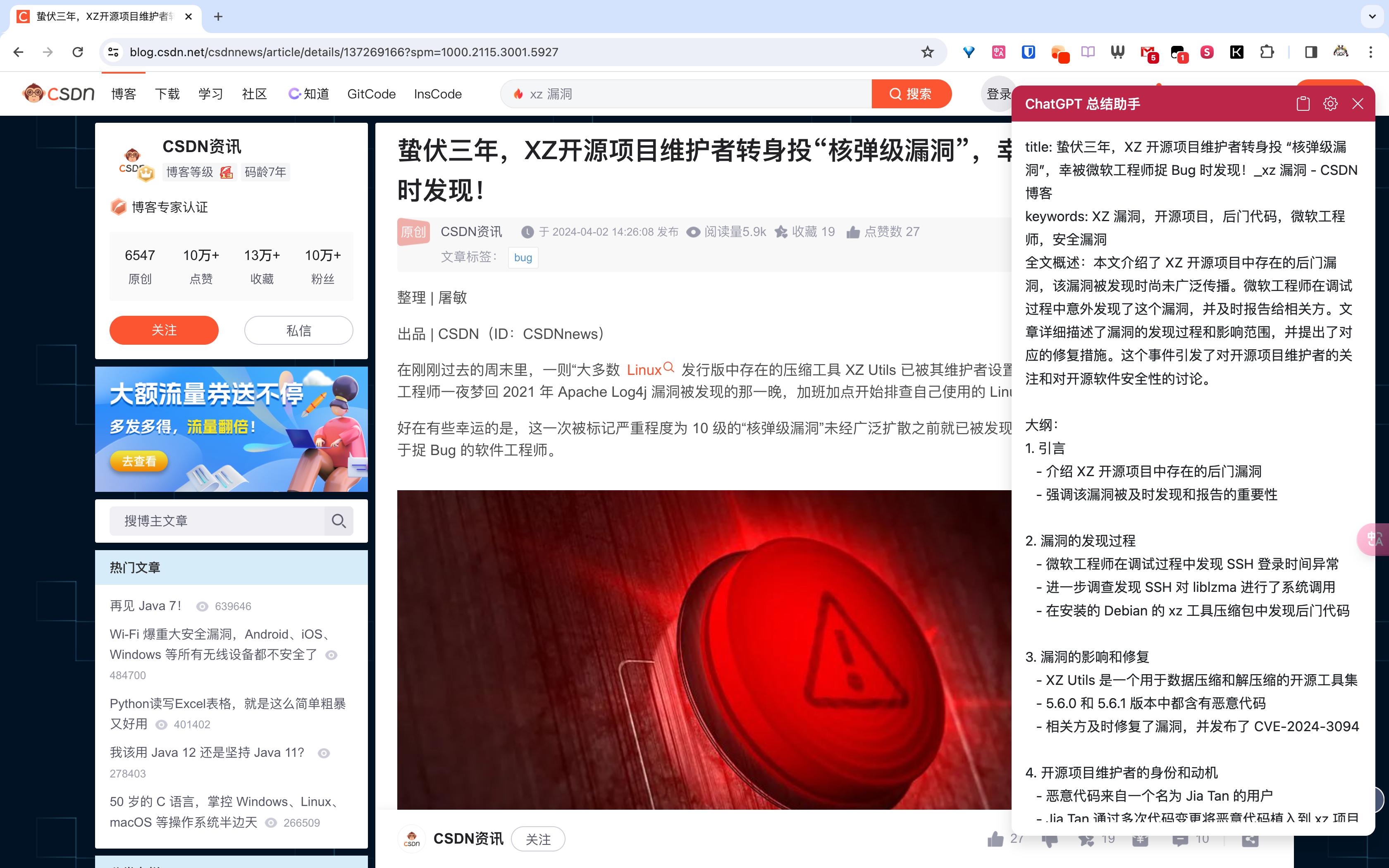
Kimi Copilot 同样支持一键总结网页内容。Kimi 是最近发布的国产大模型,对于上面的 ChatGPT 总结助手,多了可以继续深入沟通的功能。并且 Kimi 支持 20 万上下文,目前 Kimi 暂时免费使用。
Chrome 还有非常多类似的插件,主要就是可以快速判断一篇长文是否值得阅读,避免浪费生命,读得稀碎。
RSS 信息源如何收藏整理?
纵使你有再丰富的 RSS 信息源,了解到了足够的新知识。如果不做好整理归纳依旧无法形成生产力,毕竟 RSS 信息源属于碎片化知识,
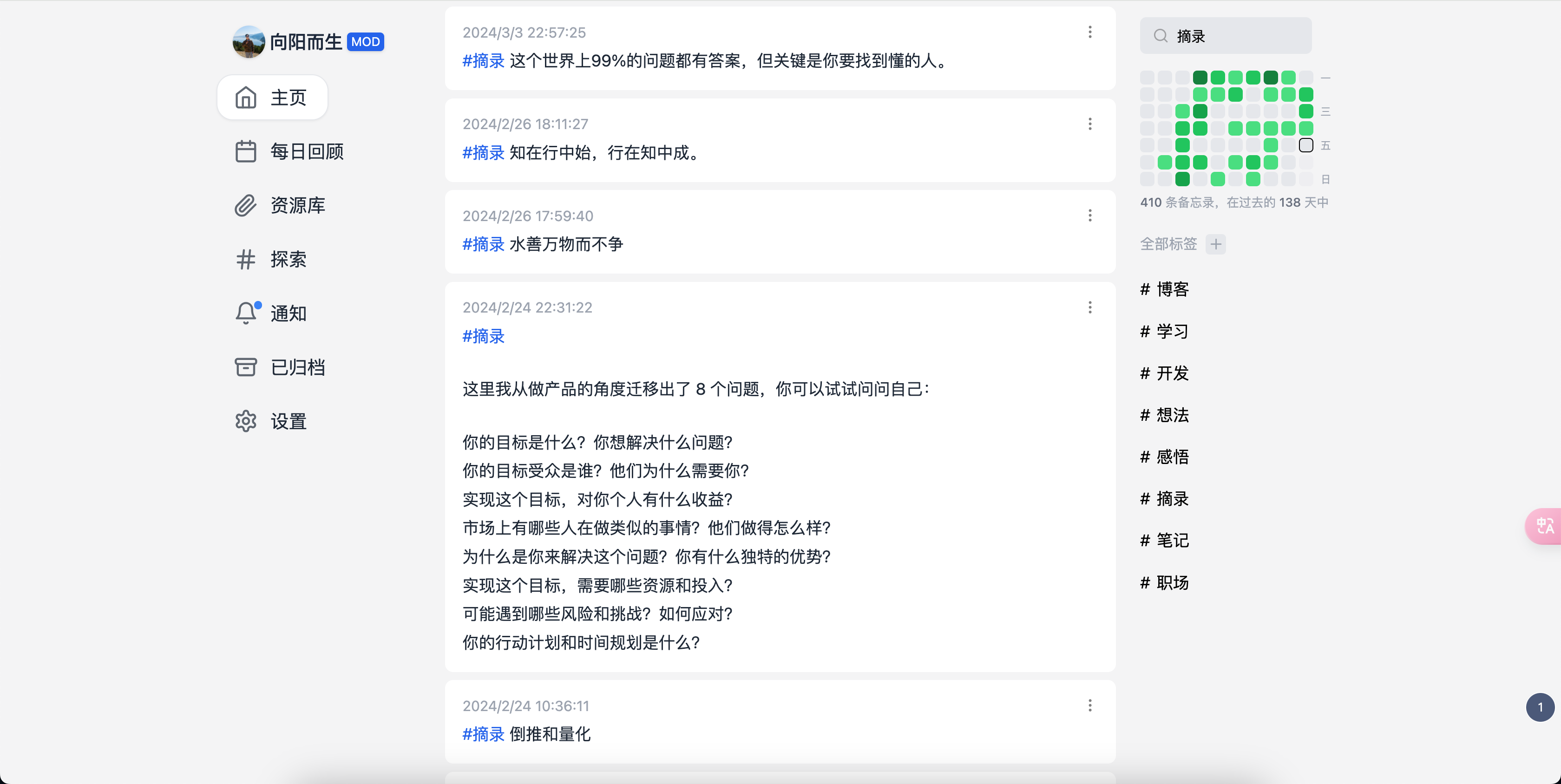
如果遇见优秀的文章,一般我都是先使用 wallabag 标记保存稍后深入阅读。如果发生灵感还可以顺手使用 memos 快速记录灵感,以便日后写作整理使用。

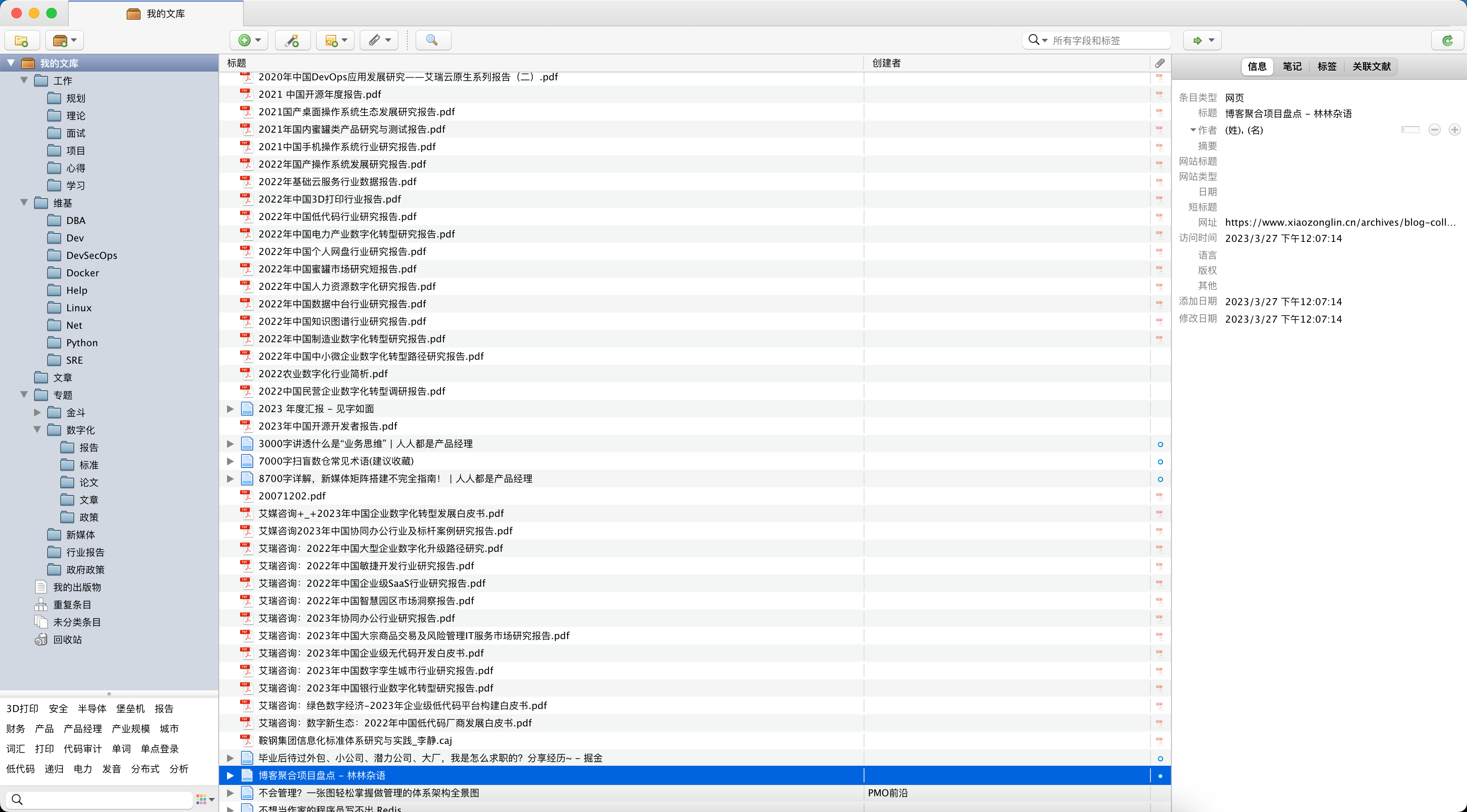
当然如果需要进一步深度归档,方便日后查阅,可以借助 Zotero 文献管理工具。
深度信息源
深度信息源指那些可以提供系统性知识结构、深入分析和全面讨论的信息源。这类信息源的载体主要为书籍、学术论文、研究报告、政策文件等,它们能够提供比碎片化信息更全面的知识和见解,有助于帮助我们深入理解和研究特定领域。
如何读好一本书?
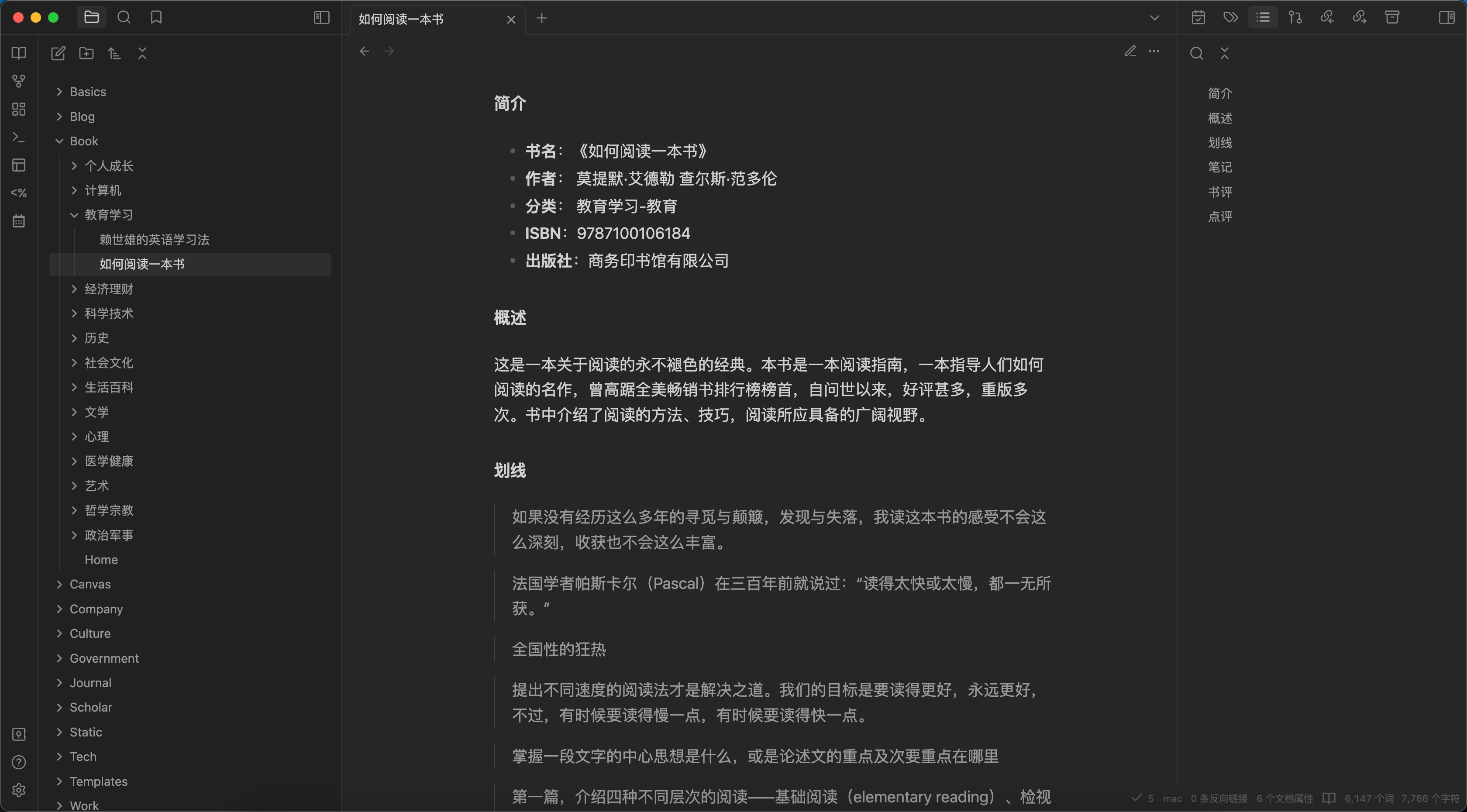
我特别推荐《如何阅读一本书》,一定要尝试深入实践书中关于「主题阅读」的部分。如果读完一遍后,可以通过复读和刻意练习对于加深理解是非常有帮助的。
我依旧是强烈建议带着问题的阅读,这对知识的内化至关重要。读完后,可以通过分享读书笔记的方式来进一步加深印象和理解。我在这方面也有一些实践经验,尤其是如何更好地「数字化」处理阅读时的思考和笔记。很多人应该会发现,阅读时的思考往往难以在写笔记的时候完整回溯,想不起来了。而且从微信读书中一个个整理划线的内容也比较繁琐。
我是采用了 Obsidian + Weread 微信读书插件,将微信读书的划线笔记和评价同步至我的 Wiki 内,然后通过我的 X·Eden 分享。如下图所示,这种方法完美解决了我在阅读和思考过程中的笔记「数字化」问题,同时书评也可以同步哦。这样一来,实际上也就不需要写读书笔记了 ~
关于 Zotero 和 Obsidian 的具体使用方法,这里我就不具体的展开讲解了。如有感兴趣,可以深入探索东半球强大的知识管理社区——PKMer。

如何研究学术论文?专题报告?
至于如何高效开展学术研究,目前我是没有能力为你解答的。但是我想强调的是:如果工作生活遇见某一领域具体的问题,不妨问问这个领域内专业的人士,或者学会如何阅读学术论文、研究报告。
毕竟这个世界上 80% 的人,所遇见 99.9% 的问题都是存在现成的标准答案。
高密度信息源
高密度信息源是深度信息源的延伸,它主要通过人与人之间的交流互动来实现。例如专题视频、面对面沟通、研讨座谈会等形式。与深度信息源相比,具有更加直接和全面的信息传递能力。
例如抖音直播连线就是一种简单高效的方式。尽管很多时候社会舆论抨击抖音 = 奶头乐,但实际上,也有一些非常优秀的人,曾经被大家广泛认可过。我们可能只需要花费几百块钱,就可以直接连线沟通交流。当然如果线下也想结交这样优秀的人,首先自己一定要拥有相应的潜力,这样更容易吸引和融入到优秀的圈子里。
其实博客也是一种非常简单高效的方式,而且不止博客有十年之约,高校教授们也有 科学网博客。尽管网站有「研究生」门槛限制,不过都能围观了解,进而接触到高密度的信息源。
同时中国大学 Mooc 和世界顶尖大学的公开课,都是互联网时代的重要信息源。如果放在二十年前,这样的资源绝对是想都不敢想的事情。虽然线上课堂缺少了交互性,可是现如今几乎所有的教授都会基于邮箱沟通交流,关键在于你愿不愿意?
还可以广泛认识社会中各层次,各种角色的人,并通过交流不断尝试换位思考,我们可以深入体会每个人的思想。与优秀和高能量的人交流,会潜移默化地影响,改变我们的思想及行为模式。更进一步如果你可以广结善缘,三百六十行结交各路好汉,足够击穿任何形式的隔阂,所谓的「信息茧房」不过只是一层窗户纸罢了。
正如古语所言:「三人行,必有我师焉;择其善者而从之,其不善者而改之。」
我们应该始终保持一种开放的心态,无论是好的还是不好的,都应该主动寻求和接触多样化的信息源。